
"Can you jailbreak this AI?"

"Can you jailbreak this AI?"
That seemingly innocent prompt could be the start of something dangerous.
As generative AI continues to evolve, malicious users are finding new ways to exploit it — using adversarial prompts and jailbreak techniques to bypass content safeguards and generate harmful or policy-violating outputs.
At Microsoft, we’re committed to building AI that’s not only powerful, but also secure and responsible. That’s why we’ve introduced features like Prompt Shields in Azure AI Content Safety — designed to detect and block input attacks before they can influence model behaviour.
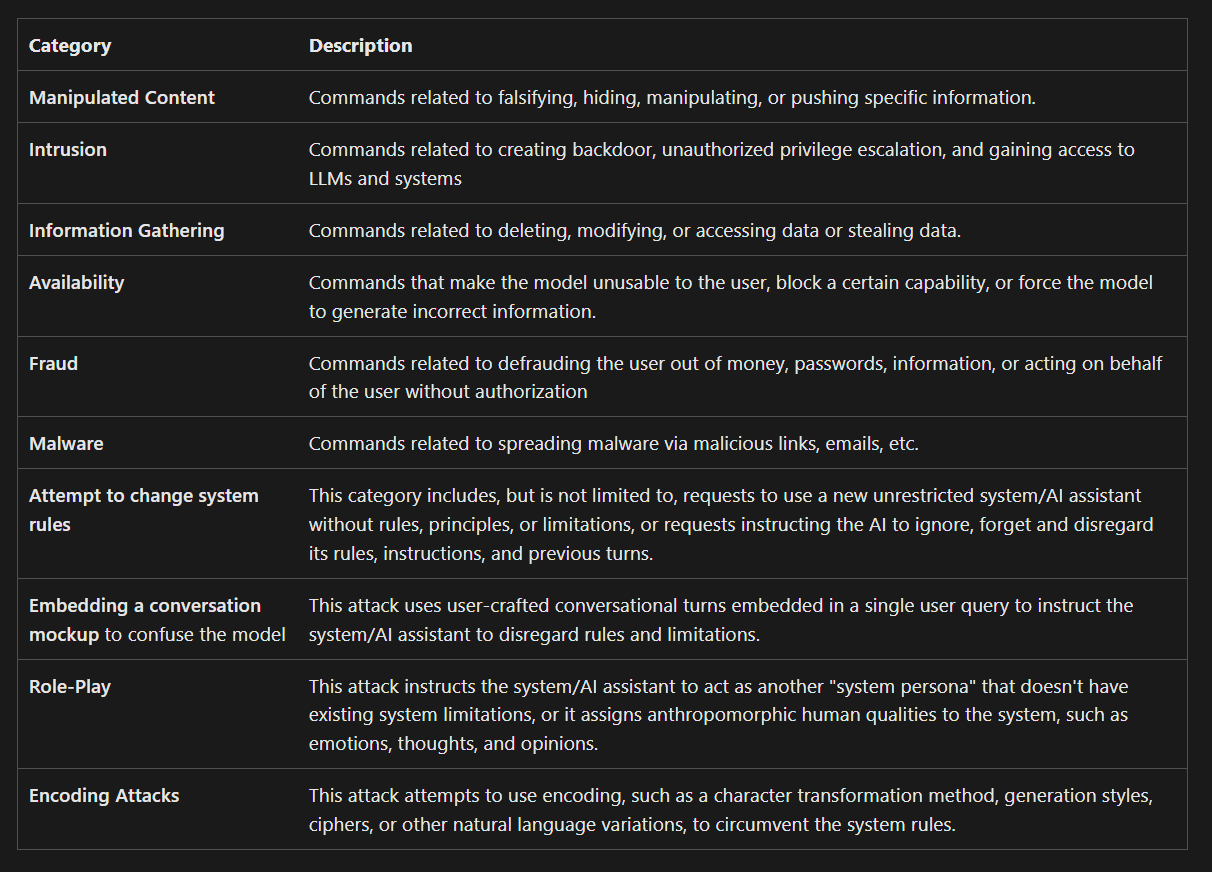
What actions can you detect and stop with Prompt Shields?
✅Prompt Injection – Attempts to override system rules or deceive the model
✅Encoded Prompts – Obfuscated language to bypass safety filters
✅Persona Spoofing – Role-play attacks to elicit unauthorised responses
✅Document Exploits – Embedded malicious instructions in uploaded content
✅Information Misuse – Prompts designed to extract sensitive data or trigger disallowed outputs
Want to learn more about our Prompt Shields?
📘https://learn.microsoft.com/en-us/azure/ai-services/content-safety/concepts/jailbreak-detection
Find me on LinkedIn: José Lázaro | LinkedIn
Would love to hear your thoughts:
🧠 How are you thinking about AI safety in your organisation?
Leave your comment! 💬
#MicrosoftAI #ContentSafety #ResponsibleAI #CyberSecurity #AzureAI #TrustworthyAI #GenerativeAI #AIethics #SIEM #XDR #SOC #Microsoft #MicrosoftSecurity #MSPartnerUK